Introduction
This post is, once again, an aide-mémoire to record a work-in-progress: porting the tools that convert Knuth’s original Pascal-based WEB source to C – to create a native build of Web2C.exe, fixwrites.exe and other tools using Microsoft’s Visual Studio (and not using pipes). My apologies if this post is a little unstructured but the whole task is somewhat convoluted, which may be reflected in my writing style for this post! However, I’d like to record it whilst it is fresh in my memory.
Why would anyone want to do this when there are ready-made, reliable, TeX distributions freely available? Good question. Well, for me, it’s nothing more than pure curiosity – and the fact that most British TV programs are now such mind-numbing drivel that I might as well do something productive in the evenings!
Join TUG: Just as an aside, I’m a member of the TeX User Group, TUG, so if you too would like to support TeX why not consider joining?
Another reason for writing this post is that I could not find much documentation on how to build Web2C.exe from source code – apart from these notes by Timothy Murphy, detailing the process for Macintosh-based port. Even though they were written in 1992 they were extremely helpful in filling in some of the details, so a belated thank you to Timothy Murphy – much of this post draws inspiration from that document. Piecing together the Web2c build process has been somewhat of a “programming jigsaw” – there are still gaps in my understanding but, I think, I can see the big picture even if it’s still a little hazy in some areas.
The Big Picture
The source files for TeX, and other TeX-related programs and utilities, are written using Professor Donald Knuth’s literate programming methodology. In essence, the program code (in Pascal) and documentation of the source code (in TeX) are contained within a single file, with extension .web. For example, Professor Knuth’s source code of the latest version of TeX is contained in a file called tex.web. Similarly, within the TeXLive repository (see a previous post) or on CTAN, you can find the WEB source code for the latest versions of other programs; for example:
- bibtex.web: the source code/documentation of
BiBTeX, for formatting and producing reference lists, as widely used within academic journal papers.
- mf.web: the source code/documentation of MetaFont.
- patgen.web: the source code/documentation of
patgen which “… takes list of hyphenated words and generates a set of patterns that can be used by the TeX 82 hyphenation algorithm.”
- tangle.web: the source code/documentation of
tangle, which converts a WEB file to a Pascal (i.e., extracts the source code in Pascal, not in C – that’s why Web2C exists).
- weave.web: the source code/documentation of
weave, which converts a WEB file to TeX (i.e., extracts the documentation of the program’s Pascal source code).
and other programs/utilities such as dvicopy.web, pltotf.web, tftopl.web and so forth.
What’s in a name: tangle, web and weave? I’ve not researched to find out, but I cannot help thinking that Professor Knuth drew inspiration from Sir Walter Scott when naming these programs. Scott’s poem Marmion contains the line(s) “O, what a tangled web we weave when we practice to decieve”. Maybe these programs are as literary as they are literate?
TeXLive as the source of the files for building Web2C.exe
The files I reference throughout this post can be downloaded via SVN from the TeXLive repository. If you want to browse the TeXLive repository, using the TortoiseSVN program on Windows, this post may be of help. The following screenshots show the TeXLive folders you’ll need to access for acquiring the various files I mention in this post.
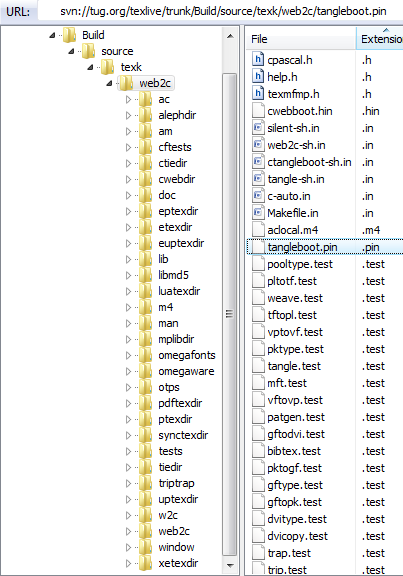
- svn://tug.org/texlive/trunk/Build/source/texk/web2c: this folder contains, for example,
tangleboot.pin (see below) and all the *.web files listed above, plus many other essential files.
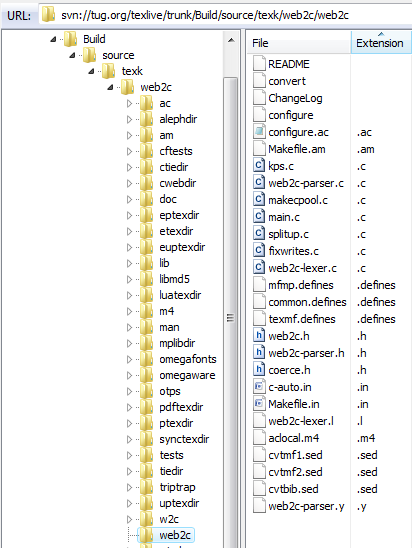
- svn://tug.org/texlive/trunk/Build/source/texk/web2c/web2c: this folder contains the source files needed to build the actual
Web2C.exe program. Note carefully it does not contain a file called Web2C.c, more on that below.
TeXLive has an advanced build-process for compiling/building all the tools and software it contains and I, for one, am in awe of the skills and expertise of its maintainers. In describing my explorations of building Web2C.exe as a Windows-based executable you need to realize that I am taking the source code files of Web2C.exe out of their “natural build environment”. What do I mean by this? Building the Web2C executable program is usually part of the much bigger TeXLive build/compilation process so you should be prepared for a little extra complexity to create Web2C.exe as a “standalone” Windows program. Note that “standalone” is in quotes because converting WEB-generated Pascal into C code requires other tools in addition to Web2C.exe: it is not fully accomplished by Web2C.exe alone.
A note about Kpathsea
The Kpathsea (path-searching) C library in an integral part of most TeX-related software and the Web2C C source files #include a number of Kpathsea headers. However, for my own purposes/experiments I’ve decided to decouple my build of the Web2C.exe executable from the need to include Kpathsea’s headers – the resulting C files generated by Web2C.exe will, of course, still depend on Kpathsea. If you grab the Web2C source files (see below) then “out of the box” you’ll need to checkout the Kpathsea library from:
svn://tug.org/texlive/trunk/Build/source/texk/kpathsea
I’ve simply not got the time to document everything I had to do to decouple Kpathsea when building Web2C.exe. It mainly involved commenting out various #include lines that pulled in Kpathsea headers and placing a few #define statements into my local version of web2c.h – plus creating some typedefs and adding a few macros. If you’re an experienced C programmer it is unlikely to present difficulties. As mentioned, this post describes a work-in-progress to satisfy my own curiosity and is meant to share a few of the things I’ve learnt, should they be useful to anyone as a starting point for their own work.
Web2C: so what is it?
Let me be clear that when I refer to Web2C I am referring to the executable program which undertakes the first (main) step in converting Pascal code into to C. So let’s now start to take a look at the details but start with a summary of “Where are we?”
Where are we?
The starting point for generating C code is to extract the Pascal code from WEB source files and that is accomplished using the tangle program. However, where do we get a working tangle program from to start with – do we have a chicken and egg problem? tangle is itself distributed in WEB source code (tangle.web), so if I need tangle to extract tangle’s source code from tangle.web, how do I create a working tangle program? Well, of course, this is solved by the distribution of tangle’s Pascal code in a file called tangleboot.pin within the Web2C directory of the TeXLive repository (see above). In essence, tangleboot.pin let’s you “bootstrap” the whole Web2C process by creating a working tangle.exe which you can use to generate the Pascal from WEB source files. Hence the name tangleboot.pin
So, how do I go from tangleboot.pin to a working tangle.exe? You need to build Web2C.exe and some associated utility programs (e.g., fixwrites.exe).
Where are the Web2C.exe source files?
As mentioned above, the TeXLive folder containing the source files needed to build Web2C.exe is
- svn://tug.org/texlive/trunk/Build/source/texk/web2c/web2c
The C source files you need to compile/build Web2C.exe are:
- kps.c
- main.c
- web2c-lexer.c
- web2c-parser.c
Some notes on these files
These C files #include a number of header files from the TeXLive distribution, notably from the Kpathsea library, so you should definitely look through them to determine any additional files you need.
The files web2c-parser.c and web2c-lexer.c are worthy of some explanation because they are the core files which drive the Pascal –> C conversion process. However, these two C source files are not hand-coded but are generated from two further source files with similar names. If you look among the source files you will also notice these two additional files:
web2c-lexer.lweb2c-parser.y
What are these files with similar names? As you may infer from their names, these files are a lexical analyser and a parser generator and require additional tools to process them:
web2c-lexer.l --> web2c-lexer.c using a tool called flex.web2c-parser.y --> web2c-parser.c + web2c-parser.h using a tool called bison.
Are bison/flex available for Windows?
Fortunately they are and, at the time of writing (February 2013), you can download Windows ports of bison 2.7 and flex 2.5.37 from http://sourceforge.net/projects/winflexbison/. The executables are called win_bison.exe and win_flex.exe respectively. The win_flex.exe port of flex adds an extra command-line switch (--wincompat) so that the C code it generates uses the standard Windows header io.h instead of unistd.h (which is used on Linux). You can also download older versions of bison and flex for Windows from the GnuWin32 project.
I have not yet tried to use the code generated by win_flex.exe and win_bison.exe but to the best of my (current) knowledge the command-line options you need are:
win_bison -y -d web2c-parser.y to generate the parser (you’ll get different file names on output: y.tab.c and y.tab.h)win_flex --wincompat web2c-lexer.l to generate the lexical analyser (you’ll get a different file name on output: lex.yy.c)
You need more than just Web2c.exe…
Assuming that you successfully build Web2c.exe, it is still not the end of the story. Although Web2c.exe does the bulk of the work in converting the Pascal to C, some initial pre-processing of the Pascal source file is needed before you can run it through Web2C.exe, and some further post-processing of the C code output by Web2C.exe is also needed. The details of how these pre- and post-processing steps actually work are contained within an important BASH shell script called convert (it has no extension) – convert is located within the TeXLive folder containing the Web2C source files. I readily confess that I know very little about Linux shell scripting so if you are well-versed in shell scripts no doubt you can easily understand what is going on in the convert file. However, here are pointers to get you started.
Pre-processing: adding the *.defines files to the Pascal file
Before you can actually run Web2C.exe on the Pascal file generated from WEB sources you need to concatenate the Pascal source file with some files having the extension “.defines“: you add these files to the start of the Pascal file before running Web2C.exe. There are several .defines contained in the Web2C source directory including:
common.definesmfmp.definestexmf.defines
The convert script checks which program, and its options, (TeX, MetaFont, BiBTeX etc) is being built and concatenates the appropriate *.defines file(s) to the start of the corresponding Pascal file. At this time, I don’t quite fully understand how/why these files are needed, but for the full details you need to read convert. By way of an example, when processing tangleboot.pin I added the file common.defines to the beginning of tangleboot.pin.
Post-processing: fixwrites.exe
Web2C.exe‘s output is not quite pure C source code – it may still contain some fragments of Pascal which need a specialist post-processing step to fully convert them to C: enter fixwrites.exe. fixwrites.exe post-processes Web2C.exe‘s C output to “…convert Pascal write/writeln’s into fprintf’s or putc’s” (see fixwrites.c).
Notes on web2c-parser.c, web2c-lexer.c and
main.c
Upon reading the convert script, and when I first ran Web2C.exe, it became readily apparent that the whole Pascal –> C tool chain (driven by convert) communicates using pipes) with stdout/stderr. The output of one program is “piped” into the input to another, rather than writing the data out to a physical disc file and then reading it back in. My personal preference, certainly whilst learning, is to output data to a file so that I can capture what’s going on.
main.c and yyin
Without going into too much detail, I needed to make a number of changes in main.c so that the lexical analyzer web2c-lexer.c was set to read it’s data from a disc file rather than through pipes/stdin. The FILE* variable you need to set/define is called yyin. For example, within main.c there is a function called initialize () which can be used to set yyin. For example:
void initialize (void)
{
register int i;
for (i = 0; i < hash_prime; hash_list[i++] = -1)
;
yyin = xfopen("your_path_to\\tangleboot.p","r");
...
...
}
In addition, within main.c there's a small function called normal () which does the following:
void normal (void)
{
out = stdout;
}
The normal () function is called from within web2c-parser.c to set the output file (FILE *out) to stdout. At present, I'm not sure precisely why this is done, but I guess it is part of the piping between programs as driven by the convert process. For example, code within convert uses sed (the stream editor).
Other output redirections happen in web2c-parser.c and you can search for these by looking for out = 0. Tracking down and locating these output redirections certainly helped me to better understand the flow of the programs.
In conclusion
This post is a little disjointed in places and light on detail in a number of areas, reflecting my own (currently) incomplete understanding of the relatively complex processes involved in converting WEB/Pascal to C. Nevertheless, I hope that it is of some use to someone, at some point. As my understanding develops I'll try to fill in the gaps with future posts.