
Introduction
In a previous post I promised to write a short introduction to libotf; however, before discussing libotf I need to “set the scene” and write something about logical vs display (visual) order and “shaping engines”. This post covers a lot of ground and I’ve tried to favour being brief rather than providing excessive detail: I hope I have not sacrificed accuracy in the process.
Logical order, display order and “shaping engines”
Logical order and display order
Imagine that you are tapping the screen of your iDevice, or sitting at your computer, writing an e-mail text in some language of your choice. Each time you enter a character it goes into the device’s memory and, of course, ultimately ends up on the display or stored in a file. The order in which characters are entered and stored by your device, or written to a text file, is called the logical order. For simple text written in left-to-right languages (e.g., English) this is, of course, the same order in which they are displayed: the display order (also called the visual order). However, for right-to-left languages, such as Arabic, the order in which the characters are displayed or rendered for reading is reversed: the display (visual) order is not the same as the logical order.
Arabic Unicode ranges
The Unicode 6.1 Standard allocates several ranges to Arabic (ignoring the latest Unicode 6.1 additions for Arabic maths). These are:
- Arabic
- Arabic Supplement
- Arabic Extended-A (new for Unicode 6.1)
- Arabic Presentation Forms-A
- Arabic Presentation Forms-B
The important point here is that for text storage and transfer, Arabic should be encoded/saved using the “base” Arabic Unicode range of 0600 to 06FF. (Caveat: I believe this is true but, of course, am not 100% certain. I’d be interested to know if this is indeed not the case.) However, I’ll assume this principle is broadly correct.
If you look at the charts you’ll see that the range 0600 to 06FF contains the isolated versions of each character; i.e., none of the glyph variations used for fully joined Arabic. So, looking at this from, say, LuaTeX’s viewpoint, how is it that the series of isolated forms of Arabic characters sitting in a TeX file in logical order can be transformed into typeset Arabic in proper visual display order? The answer is that the incoming stream of bytes representing Arabic text has to be “transformed” or “shaped” into the correct series of glyphs.
A little experiment
Just for the moment, assume that you are using the LuaTeX engine but with the plain TeX macro package: you have no other “packages” loaded but you have setup a font which has Arabic glyphs. All the font will do is allow you to display the characters that LuaTeX sees within its input stream. If you enter some Arabic text into a TeX file, what do you think will happen? Without any additional help or support to process the incoming Arabic text LuaTeX will simply output what is gets: a series of isolated glyphs in logical (not display) order:
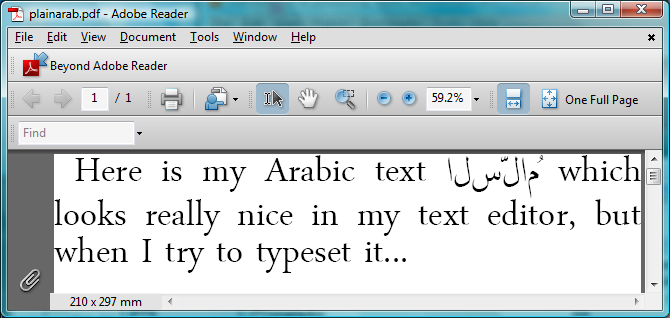
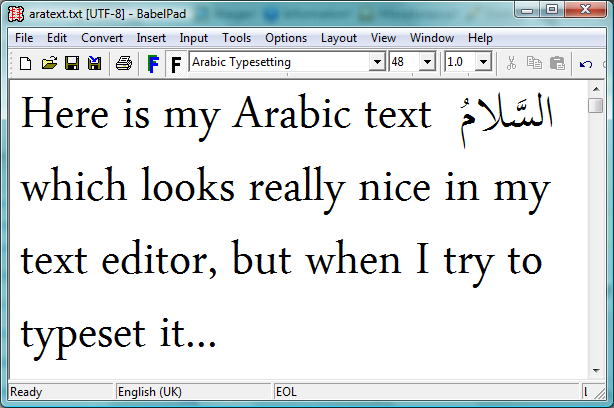
But it looked perfect in my text editor…:
Shaping engines
What’s happening is that the text editor itself is applying a shaping engine to the Arabic text in order to render it according to the rules of Arabic text processing and typography: you can think of this as a layer of software which sits between the underlying text and the screen display: transforming characters to glyphs. The key point is that the core LuaTeX engine does not provide a “shaping engine”: i.e., it does not have an automatic or built-in set of functions to automatically apply the rules of Arabic typesetting and typography. The LuaTeX engine needs some help and those rules have to be provided or implemented through packages, plug-ins or through Lua code such as the ConTeXt package provides. Without this additional help LuaTeX will simply render the raw, logical order, text stream of isolated (non-joined) characters.
Incidentally, the text editor here is BabelPad which uses the Windows shaping engine called Uniscribe, which provides a set of “operating system services” for rendering complex scripts.
Contextual analysis
Because Arabic is a cursive script, with letters that change shape according to position in a word and adjacent characters (the “context”), part of the job of a “shaping engine” is to perform “contextual analysis”: looking at each character and working out which glyph should be used, i.e., the form it should take: initial, medial, final or isolated. The Unicode standard (Chapter 8: Middle Eastern Scripts ) explores this process in much more detail.
If you look the Unicode code charts for Arabic Presentation Forms-B you’ll see that this Unicode range contains the joining forms of Arabic characters; and one way to perform contextual analysis involves mapping input characters (i.e., in their isolated form) to the appropriate joining form version from within the Unicode range Arabic Presentation Forms-B. After the contextual analysis is complete the next step is to apply an additional layer of shaping to ensure that certain ligatures are produced (such as lam alef). In addition, you then apply more advanced typographic features defined within the particular (OpenType) font you are using: such as accurate vowel placement, cursive positioning and so forth. This latter stage is often referred to as OpenType shaping.
The key point is that OpenType font technology is designed to encapsulate advanced typographic rules within the font files themselves, using so-called OpenType tables: creating so-called “intelligent fonts”. You can think of these tables as containing an extensive set of “rules” which can be applied to a series of input glyphs in order to achieve a specific typographic objective. This is actually a fairly large and complex topic, which I’ll cover in a future post (“features” and “lookups”).
Despite OpenType font technology supporting advanced typography, you should note that the creators of specific fonts choose which features they want to support: some fonts are packed with advanced features, others may contain just a few basic rules. In short, OpenType fonts vary enormously so you should never assume “all fonts are created equal”, they are not.
And finally: libotf
The service provided by libotf is to apply the rules contained in an OpenType font: it is an OpenType shaping library, especially useful with complex text/scripts. You pass it a Unicode string and call various functions to “drive” the application of the OpenType tables contained within the font. Of course, your font needs to support or provide the feature you are asking for but libotf has a way to “ask” the font “Do you support this feature?” I’ll provide further information in a future post, together with some sample C code.
And finally, some screenshots
We’ve covered a lot of ground so, hopefully, the following screenshots might help to clarify the ideas presented above. These screenshots are also from BabelPad which has the ability to switch off the shaping engine to let you see the raw characters in logical order before any contextual analysis or shaping is applied.
The first screenshot shows the raw text in logical order before any shaping has been applied. This is the text that would be entered at the keyboard and saved into a TeX file. It is the sequence of input characters that LuaTeX would see if it read some TeX input containing Arabic text.
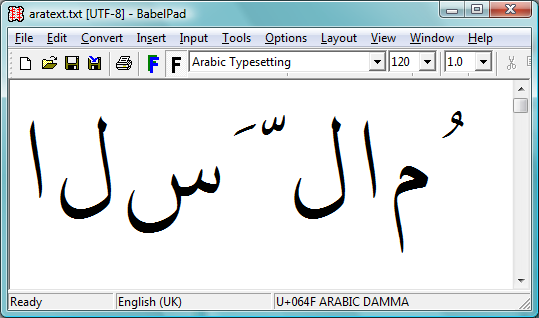
The following screenshot is the result of applying the Windows system shaping engine called Uniscribe. Of course, different operating systems have their own system services to perform complex shaping but the tasks are essentially the same: process the input text to render the display version, through the application of rules contained in the OpenType font.
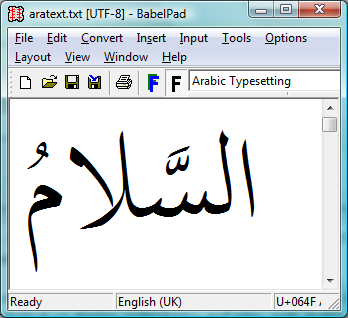
One more screenshot, this time from a great little tool that I found on this excellent site.
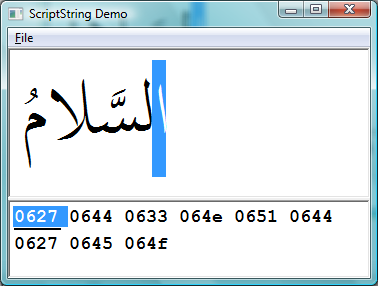
The top section of the screenshot shows the fully shaped (i.e., via Uniscribe) and rendered version of the Unicode text shown in the lower part of the screen. Note carefully that the text stream is in logical order (see the highlighted character) and that the text is stored using the Unicode range 0600 to 06FF.
Summary
These posts are a lot of work and take quite some hours to write; so I hope that the above has provided a useful, albeit brief, overview of some important topics which are central to rendering/displaying or typesetting complex scripts.