
The C source code of the once commercial Y&Y TeX distribution (for Windows) was donated to the TeX User Group after Y&Y TeX Inc ceased trading. I bought a copy the Y&Y TeX system in the late 1990s and certainly found it to be an excellent distribution. The source C code is free to download from http://code.google.com/p/yytex/. If you are interested to explore the inner workings of TeX and want an easy to build/compile Windows code base then this should be of real interest. Note that the DVI viewer, DVIWindo, makes use of Adobe Type Manager libraries which are not included in the download; in addition, binaries are not provided so you’ll need to compile them.
Introduction to logical vs display order, and shaping engines
Introduction
In a previous post I promised to write a short introduction to libotf; however, before discussing libotf I need to “set the scene” and write something about logical vs display (visual) order and “shaping engines”. This post covers a lot of ground and I’ve tried to favour being brief rather than providing excessive detail: I hope I have not sacrificed accuracy in the process.
Logical order, display order and “shaping engines”
Logical order and display order
Imagine that you are tapping the screen of your iDevice, or sitting at your computer, writing an e-mail text in some language of your choice. Each time you enter a character it goes into the device’s memory and, of course, ultimately ends up on the display or stored in a file. The order in which characters are entered and stored by your device, or written to a text file, is called the logical order. For simple text written in left-to-right languages (e.g., English) this is, of course, the same order in which they are displayed: the display order (also called the visual order). However, for right-to-left languages, such as Arabic, the order in which the characters are displayed or rendered for reading is reversed: the display (visual) order is not the same as the logical order.
Arabic Unicode ranges
The Unicode 6.1 Standard allocates several ranges to Arabic (ignoring the latest Unicode 6.1 additions for Arabic maths). These are:
- Arabic
- Arabic Supplement
- Arabic Extended-A (new for Unicode 6.1)
- Arabic Presentation Forms-A
- Arabic Presentation Forms-B
The important point here is that for text storage and transfer, Arabic should be encoded/saved using the “base” Arabic Unicode range of 0600 to 06FF. (Caveat: I believe this is true but, of course, am not 100% certain. I’d be interested to know if this is indeed not the case.) However, I’ll assume this principle is broadly correct.
If you look at the charts you’ll see that the range 0600 to 06FF contains the isolated versions of each character; i.e., none of the glyph variations used for fully joined Arabic. So, looking at this from, say, LuaTeX’s viewpoint, how is it that the series of isolated forms of Arabic characters sitting in a TeX file in logical order can be transformed into typeset Arabic in proper visual display order? The answer is that the incoming stream of bytes representing Arabic text has to be “transformed” or “shaped” into the correct series of glyphs.
A little experiment
Just for the moment, assume that you are using the LuaTeX engine but with the plain TeX macro package: you have no other “packages” loaded but you have setup a font which has Arabic glyphs. All the font will do is allow you to display the characters that LuaTeX sees within its input stream. If you enter some Arabic text into a TeX file, what do you think will happen? Without any additional help or support to process the incoming Arabic text LuaTeX will simply output what is gets: a series of isolated glyphs in logical (not display) order:
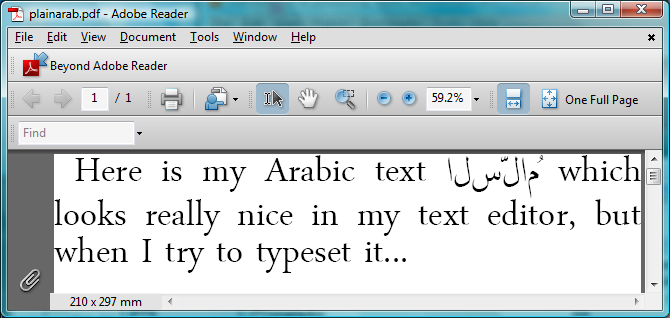
But it looked perfect in my text editor…:
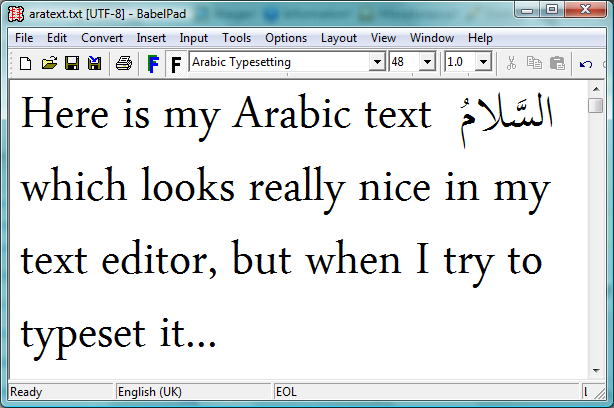
Shaping engines
What’s happening is that the text editor itself is applying a shaping engine to the Arabic text in order to render it according to the rules of Arabic text processing and typography: you can think of this as a layer of software which sits between the underlying text and the screen display: transforming characters to glyphs. The key point is that the core LuaTeX engine does not provide a “shaping engine”: i.e., it does not have an automatic or built-in set of functions to automatically apply the rules of Arabic typesetting and typography. The LuaTeX engine needs some help and those rules have to be provided or implemented through packages, plug-ins or through Lua code such as the ConTeXt package provides. Without this additional help LuaTeX will simply render the raw, logical order, text stream of isolated (non-joined) characters.
Incidentally, the text editor here is BabelPad which uses the Windows shaping engine called Uniscribe, which provides a set of “operating system services” for rendering complex scripts.
Contextual analysis
Because Arabic is a cursive script, with letters that change shape according to position in a word and adjacent characters (the “context”), part of the job of a “shaping engine” is to perform “contextual analysis”: looking at each character and working out which glyph should be used, i.e., the form it should take: initial, medial, final or isolated. The Unicode standard (Chapter 8: Middle Eastern Scripts ) explores this process in much more detail.
If you look the Unicode code charts for Arabic Presentation Forms-B you’ll see that this Unicode range contains the joining forms of Arabic characters; and one way to perform contextual analysis involves mapping input characters (i.e., in their isolated form) to the appropriate joining form version from within the Unicode range Arabic Presentation Forms-B. After the contextual analysis is complete the next step is to apply an additional layer of shaping to ensure that certain ligatures are produced (such as lam alef). In addition, you then apply more advanced typographic features defined within the particular (OpenType) font you are using: such as accurate vowel placement, cursive positioning and so forth. This latter stage is often referred to as OpenType shaping.
The key point is that OpenType font technology is designed to encapsulate advanced typographic rules within the font files themselves, using so-called OpenType tables: creating so-called “intelligent fonts”. You can think of these tables as containing an extensive set of “rules” which can be applied to a series of input glyphs in order to achieve a specific typographic objective. This is actually a fairly large and complex topic, which I’ll cover in a future post (“features” and “lookups”).
Despite OpenType font technology supporting advanced typography, you should note that the creators of specific fonts choose which features they want to support: some fonts are packed with advanced features, others may contain just a few basic rules. In short, OpenType fonts vary enormously so you should never assume “all fonts are created equal”, they are not.
And finally: libotf
The service provided by libotf is to apply the rules contained in an OpenType font: it is an OpenType shaping library, especially useful with complex text/scripts. You pass it a Unicode string and call various functions to “drive” the application of the OpenType tables contained within the font. Of course, your font needs to support or provide the feature you are asking for but libotf has a way to “ask” the font “Do you support this feature?” I’ll provide further information in a future post, together with some sample C code.
And finally, some screenshots
We’ve covered a lot of ground so, hopefully, the following screenshots might help to clarify the ideas presented above. These screenshots are also from BabelPad which has the ability to switch off the shaping engine to let you see the raw characters in logical order before any contextual analysis or shaping is applied.
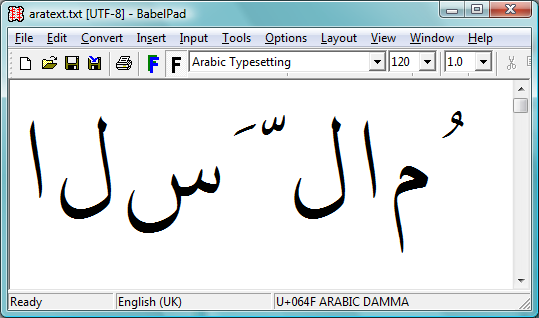
The first screenshot shows the raw text in logical order before any shaping has been applied. This is the text that would be entered at the keyboard and saved into a TeX file. It is the sequence of input characters that LuaTeX would see if it read some TeX input containing Arabic text.
The following screenshot is the result of applying the Windows system shaping engine called Uniscribe. Of course, different operating systems have their own system services to perform complex shaping but the tasks are essentially the same: process the input text to render the display version, through the application of rules contained in the OpenType font.
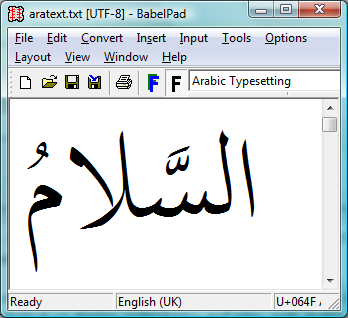
One more screenshot, this time from a great little tool that I found on this excellent site.
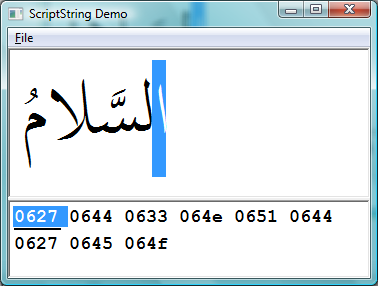
The top section of the screenshot shows the fully shaped (i.e., via Uniscribe) and rendered version of the Unicode text shown in the lower part of the screen. Note carefully that the text stream is in logical order (see the highlighted character) and that the text is stored using the Unicode range 0600 to 06FF.
Summary
These posts are a lot of work and take quite some hours to write; so I hope that the above has provided a useful, albeit brief, overview of some important topics which are central to rendering/displaying or typesetting complex scripts.
Some papers on TeX’s math typesetting algorithms
Just a brief post to share a list of papers which describe many interesting and low-level details of math typesetting, including TeX’s algorithms and math fonts.
- Appendix G Illuminated, by Bogusław Jackowski.
- Understanding the aesthetics of math typesetting, by Ulrik Vieth:
- OpenType Math Illuminated, by Ulrik Vieth.
- Math typesetting in TEX: The good, the bad, the ugly, by Ulrik Vieth.
Typesetting Arabic with LuaTeX: Part 2 (documentation, tools and libraries)
Introduction
I’ve been thinking about the next article in this series and what should it address so I’ve decided to skip ahead and give a summary of the documentation, tools and libraries which made it possible for me to experiment with typesetting Arabic. I’m listing these because it actually took a long time to assemble the reading materials and tools required, so it may just save somebody, somewhere, the many hours I spent hunting it all down. For sure, there’s a ton of stuff I want to write about, in an attempt to piece together the various concepts and ideas involved in gaining a better understanding of Unicode, OpenType and Arabic text typesetting/display. However, I’m soon to start a new job, which means I’ll have less time to devote to this blog so I’ll try to post as much as I can over the next couple of weeks.
Just for completeness, I should say that, for sure, you can implement Arabic layout/typesetting for LuaTeX in pure Lua code, as the ConTeXt distribution has done, through the quite incredible work of Idris Hamid and Hans Hagen.
Documentation
There is a lot to read. Here are some resources that are either essential or helpful.
Unicode
Clearly, you’ll need to read relevant parts of the Unicode Standard. Here’s my suggested minimal reading list.
- Chapter 8: Middle Eastern Scripts . This gives an extremely useful description of cursive joining and a model for implementing contextual analysis.
- Unicode ranges for Arabic (see also these posts). You’ll need the Unicode code charts for Arabic (PDFs downloadable and listed under Middle Eastern Scripts, here)
- Unicode Bidirectional Algorithm. Can’t say that I’ve really read this properly, and certainly not yet implemented anything to handle mixed runs of text, but you certainly need it.
OpenType
Whether you are interested in eBooks, conventional typesetting or the WOFF standard, these days a working knowledge of OpenType font technology is very useful. If you want to explore typesetting Arabic then it’s simply essential.
- Microsoft have some very useful and essential documentation. Perhaps slightly geared toward Microsoft Windows’ Uniscribe, but still extremely useful is Developing OpenType Fonts for Arabic Script.
- The OpenType Specification. This is a very technical and very dry document. Thankfully, libotf reduces your need to read too much of this but it can be very useful if you need to dive into the occasional detail.
- The FontForge web site also has a lot of useful information.
C libraries
It’s always a good idea to leverage the work of true experts, especially if it is provided for free as an open source library! I spent a lot of time hunting for libraries, so here is my summary of what I found and what I eventually settled on using.
- IBM’s ICU: Initially, I looked at using IBM’s International Components for Unicode but, for my requirements, it was serious overkill. It is a truly vast and powerful open source library (for C/C++ and Java) if you need the wealth of features it provides.
- HarfBuzz: This is an interesting and ongoing development. The HarfBuzz OpenType text shaping engine looks like it will become extremely useful; although I had a mixed experience trying to build it on Windows, which is almost certainly due to my limitations, not those of the library. If you’re Linux-based then no doubt it’ll be fine for you. As it matures to a stable release I’ll definitely take another look.
- GNU FriBidi: As mentioned above, essential for a full implementation of displaying (eBooks, browsers etc) or typesetting mixed left-to-right and right-to-left scripts is the Unicode Bidirectional Algorithm. Fortunately, there’s a free and standard implementation of this available as a C library: GNU FriBidi I’ve not yet reached the point of being able to use it but it’s the one I’ll choose.
My libraries of choice
Eventually, I settled on FreeType and libotf. You need to use them together because libotf depends on FreeType. Both libraries are mature and easy to use and I simply cannot praise these libraries too highly. Clearly, this is my own personal bias and preference but ease of use rates extremely highly on my list of requirements. FreeType has superb documentation whereas libotf does not, although it has some detailed comments within the main #include file. I’ll definitely post a short “getting started with libotf” because it is not difficult to use (when you’ve worked it out!).
libotf: words are not enough!
Mindful that I’ve not yet explained how all these libraries work together, or what they do, but I just have to say that libotf is utterly superb. libotf provides a set of functions which “drive” the features and lookups contained in an OpenType font, allowing you to pass in a Unicode string and apply OpenType tables to generate the corresponding sequence of glyphs which you can subsequently render. Of course, for Arabic you also need to perform contextual analysis to select the appropriate joining forms but once that is done then libotf lets you take full advantage of any advanced typesetting features present in the font.
UTF-8 encoding/decoding
To pass Unicode strings between your C code and LuaTeX you’ll be using UTF-8 so you will need to encode and decode UTF-8 from within your C. Encoding is easy and has been covered elsewhere on this site. For decoding UTF-8 into codepoints I use the The Flexible and Economical UTF-8 Decoder.
Desktop software
In piecing together my current understanding of Unicode and OpenType I found the following software to be indespensible. Some of these are Windows-only applications.
- VOLT: Microsoft’s excellent and free VOLT (Visual OpenType Labout Tool). I’ll certainly try to write an introduction to VOLT but you can also download the free Volt Training Video.
- Font editors: Fontlab Studio 5 (commercial) or FontForge (free).
- Adobe FDK: The Adobe Font Development Kit contains some excellent utilities and I highly recommend it.
- Character browser: To assist with learning/exploring Unicode I used the Unibook character browser.
- BabelPad: Absoutely superb Windows-based Unicode text editor. Packed with features that can assist with understanding Unicode and the rendering of complex scripts. For example, the ability to toggle complex rendering so that you can edit Arabic text without any Uniscribe shaping being applied.
- BabelMap: Unicode Character Map for Windows is another great tool from the author of BabelPad.
- High quality Arabic fonts. By “high quality” I don’t just mean the design and hinting but also the number of OpenType features implemented or contained in the font itself, such as cursive positioning, ligatures, vowel placement (mark to base, mark to ligature, mark to mark etc). My personal favourite is Arabic Typesetting (shipped with Windows) but SIL International also provide free Arabic fonts provide one called Scheherazade.
TIP: Microsoft VOLT and the Arabic Typesetting or Scheherazade fonts. I’ll talk about VOLT in more detail later but Microsoft and SIL provide “VOLT versions” of their respective Arabic fonts. These are absolutely invaluable resources for understanding advanced OpenType concepts and if you are interested to learn more I strongly recommend taking a look at them.
- The VOLT version of the Arabic Typesetting font is shipped with the VOLT installer and is contained within a file called “VoltSupplementalFiles.exe”, so just run that to extract the VOLT version.
- The VOLT version of Scheherazade is made available as a download from SIL.
I can only offer my humble thanks to the people who created these resources and made them available for free: a truly substantial amount of work is involved in creating them.
LuaCOM: connecting LuaTeX to Windows automation
Introduction
The Windows operating system provides a technology called COM, which stands for Component Object Model. In essence, it provides a way for software components and applications to “talk to each other”. That’s a gross oversimplification but it gives the general idea. It’s now an old technology but nevertheless it is still very powerful; over the years I’ve used it quite extensively for automating various publishing/production tasks. In those days it was with Perl using a module called Win32::OLE.
Of course, applications have to be written to support COM so you can think of COM-aware applications as offering a “set of services” that you can call — many applications provide the ability to call those services from scripting languages which have support for COM (via modules/plugins etc), such as Perl, Ruby and, of course, Lua via LuaCOM. A combination of COM-aware applications and scripting languages with COM support provides a very flexible way to “glue together” all sorts of different applications to create novel automated workflows/processes.
Using COM from within scripting languages is fairly straightforward but under the surface COM is, to me anyway, a complex beast indeed. The best low-level COM programming tutorials I have ever read are published on codeproject.com, written by Michael Dunn. Here’s one such tutorial Introduction to COM – What It Is and How to Use It.
LuaCOM
LuaCOM lets you use COM in your Lua scripts, i.e., it is a binding to COM. I don’t know if there are freely available builds of the latest version (probably with Windows distributions of Lua), but you can download and compile the latest version from Github.
LuaCOM is a DLL (Dynamic Link Library) that you load using the standard “require” feature of Lua. For example, to start Microsoft Word from within your Lua code, using LuaCOM, you would do something like this:
com = require("luacom")
-- should be CreateObject not GetObject!
Word =com.CreateObject("Word.Application")
Word.Visible=1
doc = Word.Documents:Open("g:/x.docx")
Naturally, the Microsoft Office applications have very extensive support for COM and offer a huge number of functions that you can call should you wish to automate a workflow process via COM from within Lua. For example, you can access all the native equation objects within a Word document (read, write, create and convert equations…). If you have watched this video and wondered how I got LuaTeX and Word to talk to each other, now you know: LuaCOM provided the glue.
Using LuaTeX to create SVG of typeset formulae
Introduction
This is a current work-in-progress so I’ll keep it brief and outline the ideas.
There are, of course, a number of tools available to generate SVG from TeX or, more correctly, SVG from DVI. Indeed, I wrote one such tool myself some 9 years ago: as an event-driven COM object which fired events to a Perl backend. For sure, DVI to SVG works but with LuaTeX you can do it differently and, in my opinion, in a much more natural and integrated way. The key is the node structures which result from typeset maths. By parsing the node tree you can create the data to construct the layout and generate SVG (or whatever you like).
Math node structures
Let’s take some plain TeX math and store it in a box:
\setbox101=\hbox{$\displaystyle\eqalign{\left| {1 \over \zeta - z - h} -
{1 \over \zeta - z} \right| & = \left|{(\zeta - z) - (\zeta - z - h) \over (\zeta - z - h)(\zeta - z)}
\right| \cr & =\left| {h \over (\zeta - z - h)(\zeta - z)} \right| \cr
& \leq {2 |h| \over |\zeta - z|^2}.\cr}$}
What does the internal node structure, resulting from this math, actually look like? Well, it looks pretty complicated but in reality it’s quite easy to parse with recursive functions, visiting each node in turn and exporting the data contained in each node. Note that you must take care to preserve context by “opening” and “closing” the node data for each hlist or vlist as you return from each level of recursion.
The idea is that you pass box101 to Lua function which starts at the root node of the box and works its way through and down the node tree. One such function might look like this:
<<snip lots of code>>
function listnodes(head)
while head do
local id = head.id
if id==0 then
mnodes.nodedispatch[id](head, hdepth+1)
elseif id==1 then
mnodes.nodedispatch[id](head, vdepth+1)
else
mnodes.nodedispatch[id](head)
end
if id == node.id('hlist') or id == node.id('vlist') then
--print("enter recursing", depth)
if id==0 then
hdepth=hdepth+1
elseif id==1 then
vdepth=vdepth+1
else
end
--mnodes.open(id, depth,head)
listnodes(head.list)
if id==0 then
mnodes.close(id, hdepth)
hdepth=hdepth-1
elseif id==1 then
mnodes.close(id, vdepth)
vdepth=vdepth-1
else
end
--print("return recursing", depth)
end
head = head.next
end
end
What you do with the data in each node depends on your objectives. My preference (current thinking) is to generate a “Lua program” which is a set of Lua functions that you can run to do the conversion. The function definitions are dictated by the conversion you want to perform. For example, the result of parsing the node tree could be something like this (lots of lines omitted):
HLISTopen(1,13295174,0,2445314,2772995,0,0,0) MATH(0,0) HLISTopen(2,0,0,0,0,0,0,0) HLISTclose(2) GLUE(skip,109224,0,0,0,0) VLISTopen(1,13076726,0,2445314,2772995,0,0,0) HLISTopen(2,13076726,0,622600,950280,0,0,0) GLUE(tabskip,0,0,0,0,0) HLISTopen(3,5670377,0,622600,950280,0,0,0) RULE(0,557056,229376) GLUE(skip,0,65536,0,2,0) MATH(0,0) HLISTopen(4,5670377,0,622600,950280,0,0,0) HLISTopen(5,5670377,0,622600,950280,0,0,0) VLISTopen(2,218453,-950280,1572880,0,0,0,0) HLISTopen(6,218453,0,393220,0,0,0,0) GLYPH(12,19,218453,0,393220) HLISTclose(6) KERN(0,0) HLISTopen(6,218453,0,393220,0,0,0,0) GLYPH(12,19,218453,0,393220) HLISTclose(6) KERN(0,0) HLISTopen(6,218453,0,393220,0,0,0,0) GLYPH(12,19,218453,0,393220) HLISTclose(6) KERN(0,0) HLISTopen(6,218453,0,393220,0,0,0,0) GLYPH(12,19,218453,0,393220) HLISTclose(6) VLISTclose(2) HLISTopen(6,2805531,0,576976,865699,0,0,0) HLISTopen(7,2805531,0,576976,865699,0,0,0) HLISTopen(8,78643,-163840,0,0,0,0,0) HLISTclose(8) VLISTopen(2,2648245,0,576976,865699,0,0,0) HLISTopen(8,2648245,0,0,422343,2,1,17) GLUE(skip,0,65536,65536,2,2) GLYPH(49,1,327681,422343,0) GLUE(skip,0,65536,65536,2,2) HLISTclose(8) KERN(266409,0) RULE(-1073741824,26214,0) KERN(145167,0) HLISTopen(8,2648245,0,127431,455111,0,0,0) GLYPH(16,7,286721,455111,127431) KERN(48355,0) GLUE(medmuskip,145632,72816,145632,0,0) GLYPH(0,13,509726,382293,54613) GLUE(medmuskip,145632,72816,145632,0,0) GLYPH(122,7,304775,282168,0) KERN(28823,0) GLUE(medmuskip,145632,72816,145632,0,0) GLYPH(0,13,509726,382293,54613) GLUE(medmuskip,145632,72816,145632,0,0) GLYPH(104,7,377591,455111,0) HLISTclose(8) VLISTclose(2) HLISTopen(8,78643,-163840,0,0,0,0,0) HLISTclose(8) HLISTclose(7) HLISTclose(6) GLUE(medmuskip,145632,72816,145632,0,0) GLYPH(0,13,509726,382293,54613) GLUE(medmuskip,145632,72816,145632,0,0) HLISTopen(6,1626950,0,576976,865699,0,0,0) HLISTopen(7,1626950,0,576976,865699,0,0,0) <<snip loads of lines>> GLYPH(58,7,182045,69176,0) HLISTclose(4) MATH(1,0) GLUE(skip,0,65536,0,2,0) HLISTclose(3) GLUE(tabskip,0,0,0,0,0) HLISTclose(2) VLISTclose(1) GLUE(skip,109224,0,0,0,0) MATH(1,0) HLISTclose(1)
At each node you can emit a “function” such as GLUE(skip,0,65536,65536,2,2) or GLYPH(49,1,327681,422343,0) which contain the node data as arguments of the function call. Each of these “functions” can then be “run” by providing a suitable function body: perhaps one for SVG, HTML5 canvas and JavaScript, or EPS file or whatever. The point is you can create whatever you like simply by emitting the appropriate data from each node.
What about glyph outlines?
Fortunately, there is a truly wonderful C library called FreeType which has everything you need to generate the spline data, even with TeX’s wonderfully arcane font encodings for the 8-bit world of Type 1 fonts. Of course, to plug FreeType into the overall solution you will need to write a linkable library: I use DLLs on Windows. FreeType is a really nice library, easy to use and made even more enjoyable by Lua’s C API.
Summary
Even though I have omitted a vast amount of detail, and the work is not yet finished, I hope you can see that LuaTeX offers great potential for new and powerful solutions.